package problem_solve;
import java.util.Scanner;
public class Boj28701 {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int n = sc.nextInt();
int sum = (1+n)*n/2;
System.out.println(sum);
System.out.println(sum*sum);
System.out.println(sum*sum);
}
}
위는 문제 풀이 코드다
여기서 제출 전에 작업해 줄 것이 2가지 있다
1. package 지우기
2. class명 Main으로 수정
제출을 위해 수정한 코드는 아래와 같다
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int n = sc.nextInt();
int sum = (1+n)*n/2;
System.out.println(sum);
System.out.println(sum*sum);
System.out.println(sum*sum);
}
}
쉽게 대학생 때 술자리에서 소주 뚜껑에 쓰여있던 숫자로 했던 업다운 게임을 푸는 알고리즘이라고 생각하면 된다
이진 탐색은 소주 뚜껑에 1~10까지의 숫자가 쓰여있다고 가정할 때 정중앙인 5나 6을 먼저 질문하고
답이 아니라면 또다시 가능한 숫자 중에 정중앙에 있는 숫자를 질문하는 방식이다
이진 탐색 개념
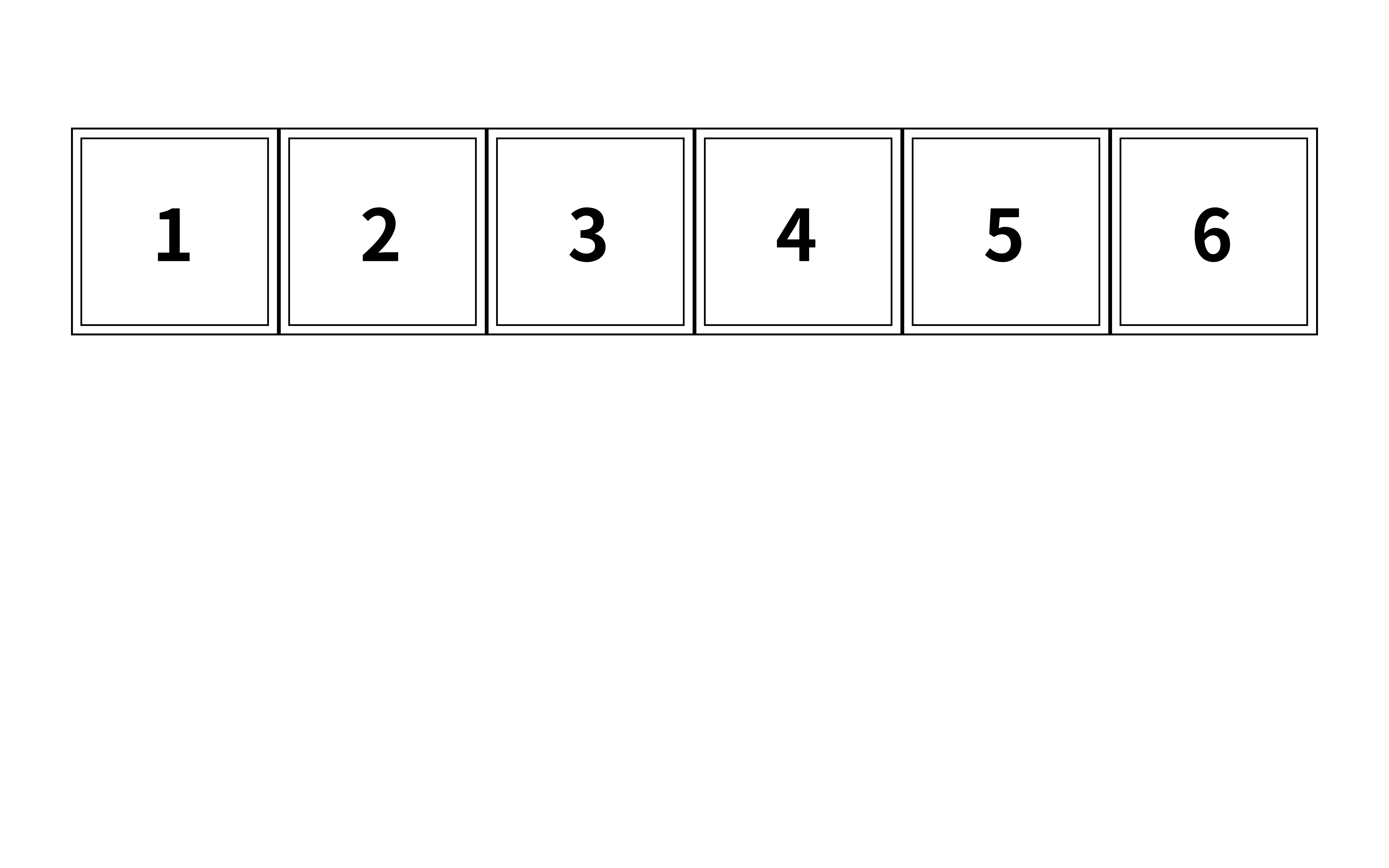
그림으로 그려보면 아래와 같다
자, 2는 어디 있을까?
모든 숫자가 빠짐없이 나열되어 있으니 너무 당연해 보인다
그렇다면 숫자가 중간중간 빠져있다면 어떨까?
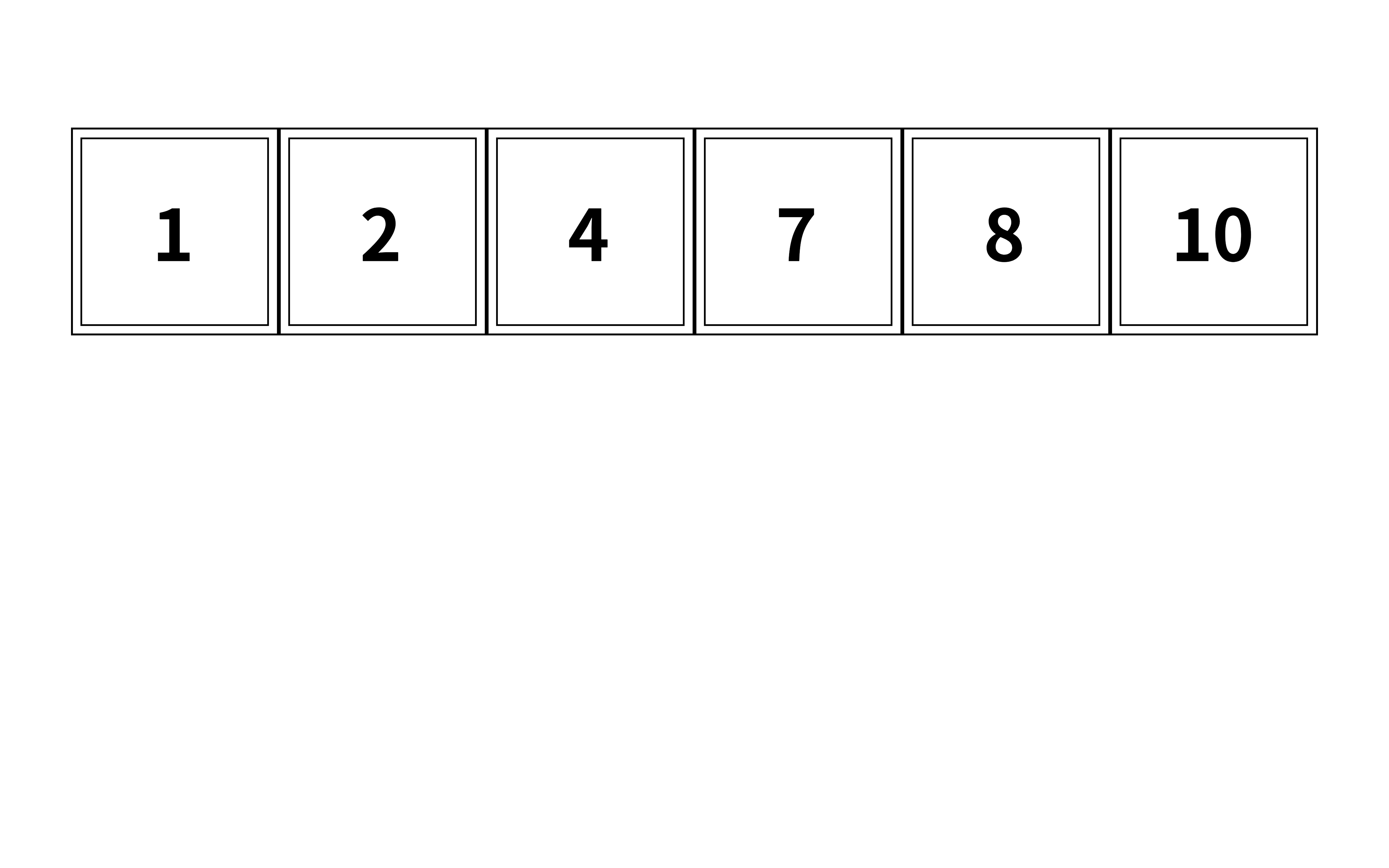
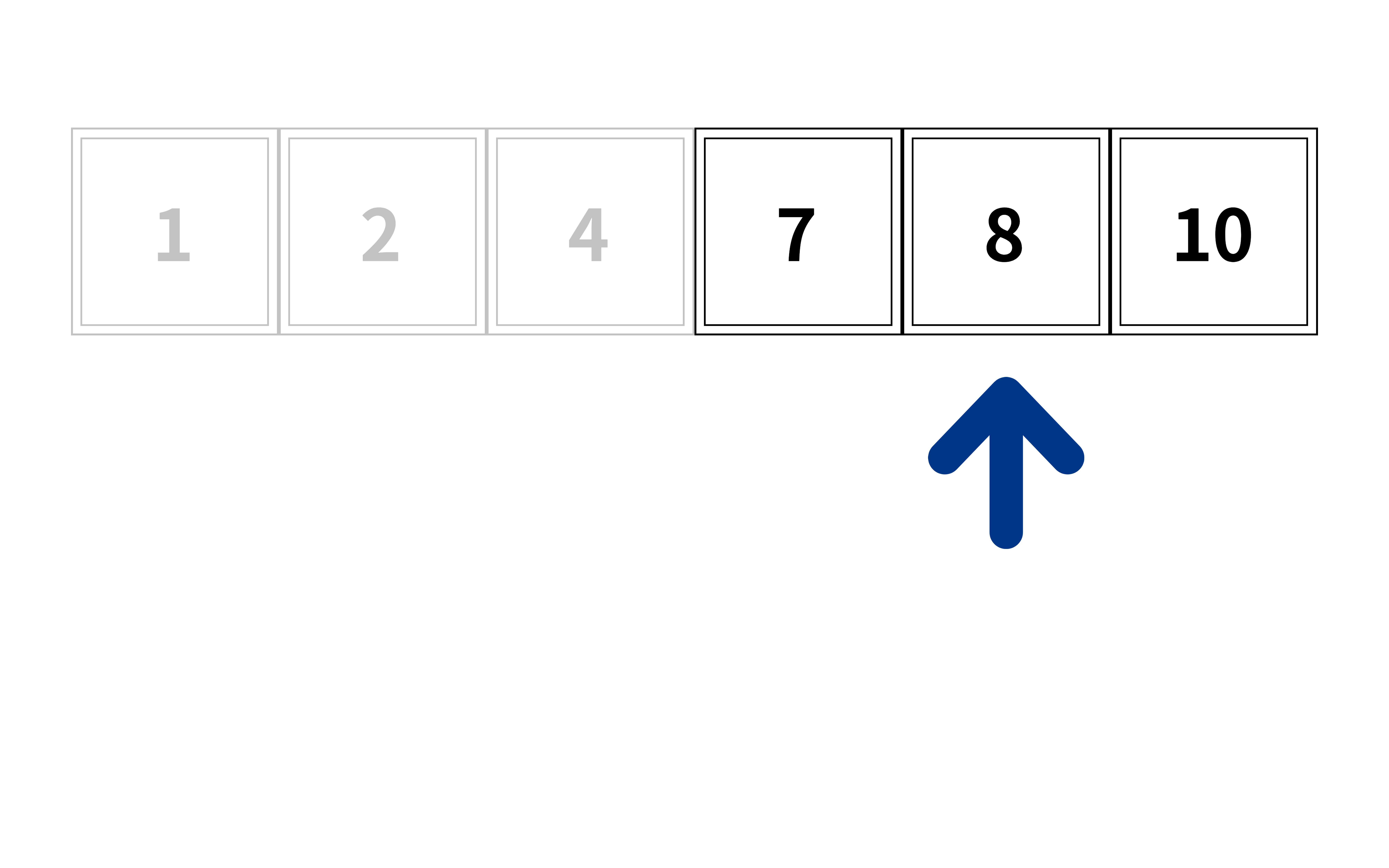
7은 어디에 있을까?
컴퓨터한테 앞에서부터 순서대로 찾으라고 시켜야 될까?
아니다 이건 너무 느리다
이진탐색을 활용해서 좀 더 빠르게 찾아보자
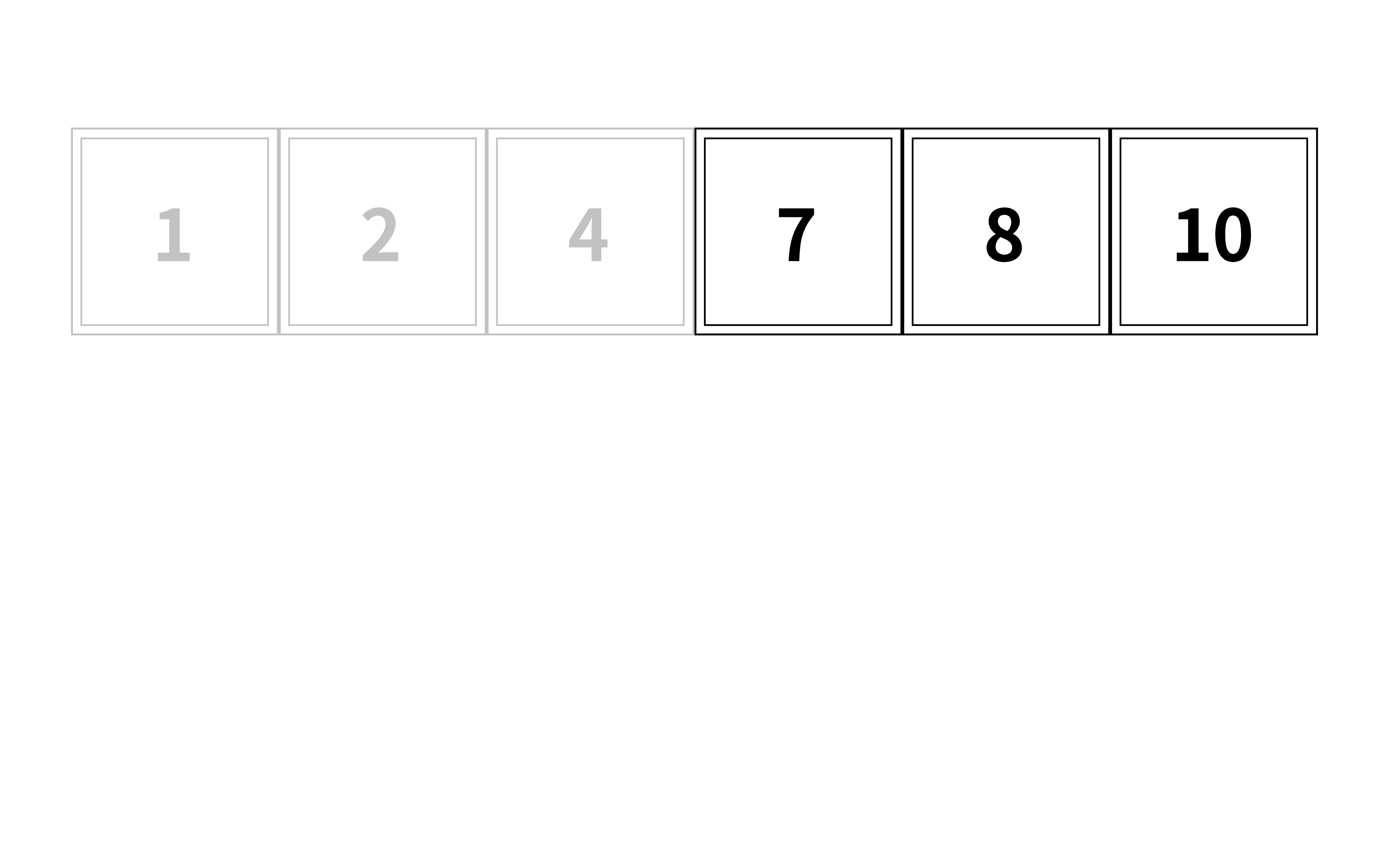
먼저 중간 지점(2개일 경우 둘 중 하나)을 먼저 확인하자
중간 지점의 값이 우리가 찾는 7인가?
그렇다면 찾은 것이고 아니라면 다음 작업을 진행한다
중간 지점의 값이 7보다 큰가?
크다면 왼쪽에 값 중에서 7을 다시 찾을 것이고
작다면 오른쪽에 값 중에서 7을 다시 찾을 것이다
이 경우엔 4<7이므로 오른쪽 값들을 보자
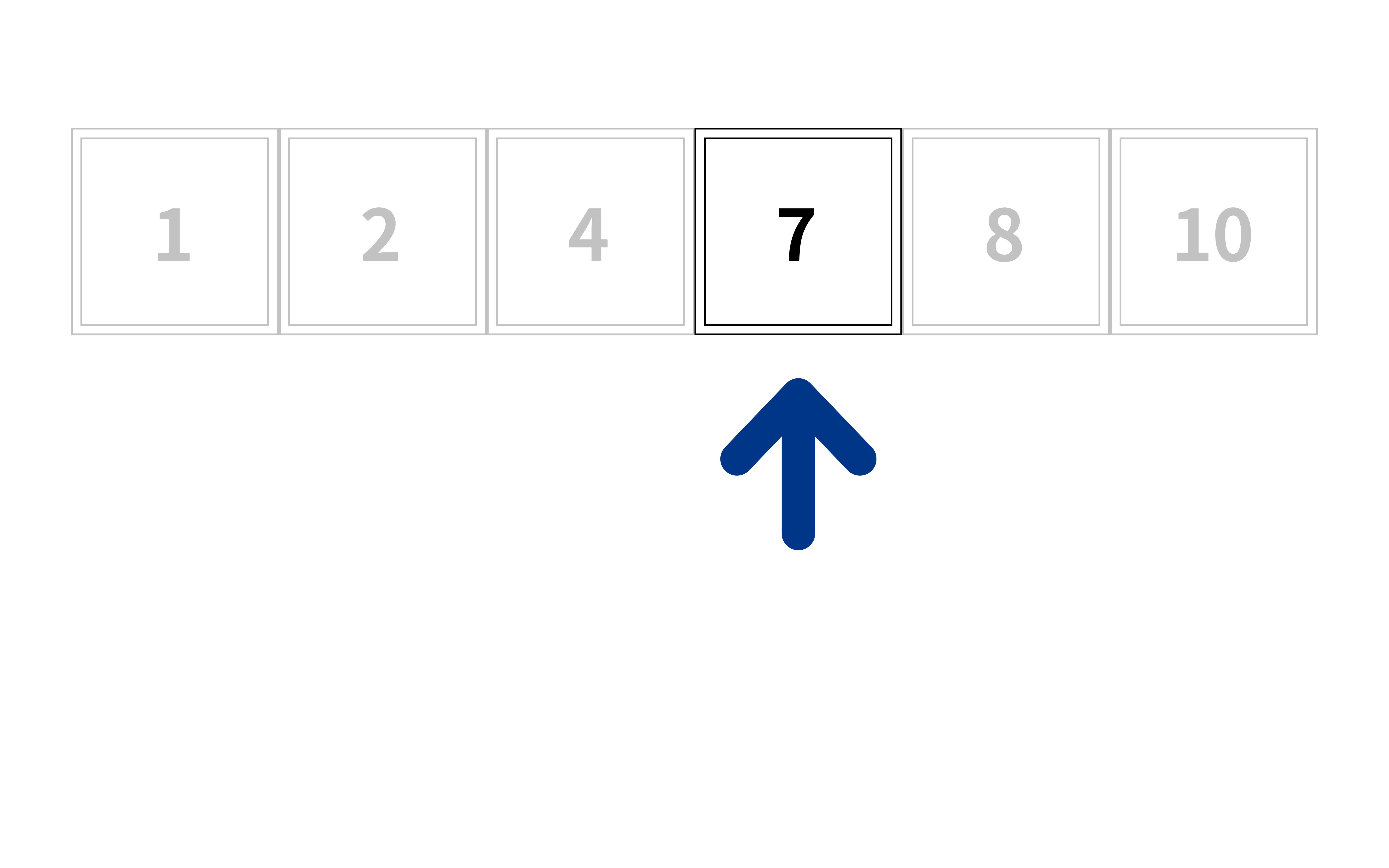
여기서부터 반복이다!
남아있는 값 중에서 중앙값을 다시 보자
7을 찾았나?
아니라면 7보다 큰가? 작은 가?
8>7이므로 이번엔 왼쪽을 보자
다시 반복한다!
남아있는 값 중에서 중앙값을 다시 보자
7을 찾았나?
네, 드디어 찾았다
이제 해당 값의 위치를 기억하면 된다
한글 코딩
이진 탐색을 실제로 코딩하기 전에 한글로 의사코딩을 해보자
datas = 테스트용 정수 배열 정의
findNum = 찾고 싶은 값
// 반복문을 돌며 각 영역에서 중간 값을 확인할 것이다
// 영역은 그때 그때 달라지므로 영역의 시작 위치와 마지막 위치를 알아야 한다
시작 위치, 마지막 위치 초기화
findIdx 찾은 위치를 저장할 변수
반복문 () {
중간 위치 = (시작 위치 + 마지막 위치) / 2
if (중간 값 == 찾는 값) {
찾았다!!
findIdx = 찾은 위치
break ;
} else if (중간 값이 찾는 값보다 작은 경우) { // 찾는 값이 중간 값보다 더 오른쪽에 있다
시작 위치 = 중간 값 + 1
} else if (중간 값이 찾는 값보다 큰 경우) { // else를 써도 된다
마지막 위치 = 중간 값 - 1;
}
}
잘 찾았는지 출력해보기!
실제 코딩
package binary_search;
public class blogging01 {
public static void main(String[] args) {
int[] datas = {1, 2, 4, 7, 8, 10};
int findNum = 7;
int start = 0;
int end = datas.length - 1;
int findIdx, mid;
while (true) {
mid = (start+end)/2;
if (datas[mid] == findNum) {
findIdx = mid;
break ;
} else if (datas[mid] < findNum) {
start = mid + 1;
} else {
end = mid - 1;
}
}
System.out.printf("찾는 값: %d, 찾은 값: %d, 찾은 위치: %d\n", findNum, datas[findIdx], findIdx);
}
}
잘 동작함을 확인할 수 있고
추가로 7이 없는 경우와 배열이 정렬되지 않은 경우에도 while문을 탈출할 수 있게 짜면 더 좋을 거 같다
public static void main(String[] args) {
int[] datas = new int[5];
datas[0] = 2;
datas[1] = 3;
datas[2] = 1;
datas[3] = 5;
datas[4] = 4;
int maxIndex = 0; // 위치
int max = 2; // 값
for (int i = 1; i < datas.length; i++) {
if (max < datas[i]) {
max=datas[i];
maxIndex = i;
}
}
System.out.printf("maxIdx: %d, maxNum: %d\n", maxIndex, max);
/*
* maxIndex max i i<5 max<datas[i]
* ===========================================================
* 0 2 1 T T
* 1 3 2 T F
* 3 T T
* 3 5 4 T F
* 5 F
* */
}
위에 코드를 아래와 같이 단순화할 수 있다
`maxIndex`만 알면 최대값을 알 수 있기 때문!
public static void main(String[] args) {
int[] datas = new int[5];
datas[0] = 2;
datas[1] = 3;
datas[2] = 1;
datas[3] = 5;
datas[4] = 4;
int maxIndex = 0; // 위치
for (int i = 1; i < datas.length; i++) {
if (datas[maxIndex] < datas[i]) {
maxIndex = i;
}
}
System.out.printf("maxIdx: %d, maxNum: %d\n", maxIndex, datas[maxIndex]);
/*
* maxIndex i i<5 datas[maxIndex]<datas[i]
* ====================================================================
* 0 1 T T
* 1 2 T F
* 3 T T
* 3 4 T F
* 5 F
* */
}
package class06;
public class Test04 {
public static void main(String[] args) {
// TODO Auto-generated method stub
/*
* 3번 문제
*
* 이 문제에서는 각 줄에서 필요한 "*"을 다 찍었다고 개행을 하고 넘어가지 않는다.
* " " 또는 "*"이 각 줄에서 정확하게 5번씩 나오는 특징이 있다.
*/
for (int a = 0; a < 5; a++) { // 총 5줄 출력할 거다.
for (int i = 0; i < 5; i++) { // 각 줄에서는 " " 또는 "*"을 무조건 5번씩 출력해야 하기에 조건문은 i < 5 이다.
if (a <= i) { // i가 a보다 크거나 같은 경우에는 "*"을 찍고 그렇지 않으면 " "를 찍어 공백을 만든다.
System.out.print("*");
} else {
System.out.print(" ");
}
}
System.out.println();
}
/*
* 디버깅 표
*
* a a<5 i i<5 a<=i
* =================================
* 0 T 0 T T
* 1 T T
* 2 T T
* 3 T T
* 4 T T
* 5 F
* 1 T 0 T F
* 1 T T
* 2 T T
* 3 T T
* 4 T T
* 5 F
* 2 T 0 T F
* 1 T F
* 2 T T
* 3 T T
* 4 T T
* 5 F
* 3 T 0 T F
* 1 T F
* 2 T F
* 3 T T
* 4 T T
* 5 F
* 4 T 0 T F
* 1 T F
* 2 T F
* 3 T F
* 4 T T
* 5 F
* 5 F
*
* */
}
}
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
// TODO Auto-generated method stub
Scanner in = new Scanner(System.in);
int n = in.nextInt();
int[] v = new int[100];
int num;
for (int i = 0; i < n; i++) {
num = in.nextInt();
System.out.println(num);
v[i] = num;
}
for (int i = 0; i < n; i++) {
System.out.println(v[i]);
}
in.close();
}
}
package problem_solve;
public class CodeUp1083 {
/*
* 3 6 9 게임은?
* 여러 사람이 순서를 정해 순서대로 수를 부르는 게임이다.
* 만약 3, 6, 9 가 들어간 수를 자신이 불러야 하는 상황이면, 대신 "박수" 를 쳐야 한다.
* 33까지 진행했다면? "짝짝"과 같이 박수를 두 번 치는 형태도 있다.
* */
public static void main(String[] args) {
// TODO Auto-generated method stub
int one, ten;
int cnt = 0;
for (int i = 0; i < 100; i++) {
one = i%10;
ten = i/10;
cnt = 0;
if (one!=0 && one%3==0) cnt++;
if (ten!=0 && ten%3==0) cnt++;
if (cnt == 0) {
System.out.println(i);
} else if (cnt == 1) {
System.out.println("박수");
} else if (cnt == 2) {
System.out.println("짝짝");
}
}
}
}
쿠버네티스에서 가장 작은 개념입니다. 하나 이상의 containers로 이루어져 있습니다.
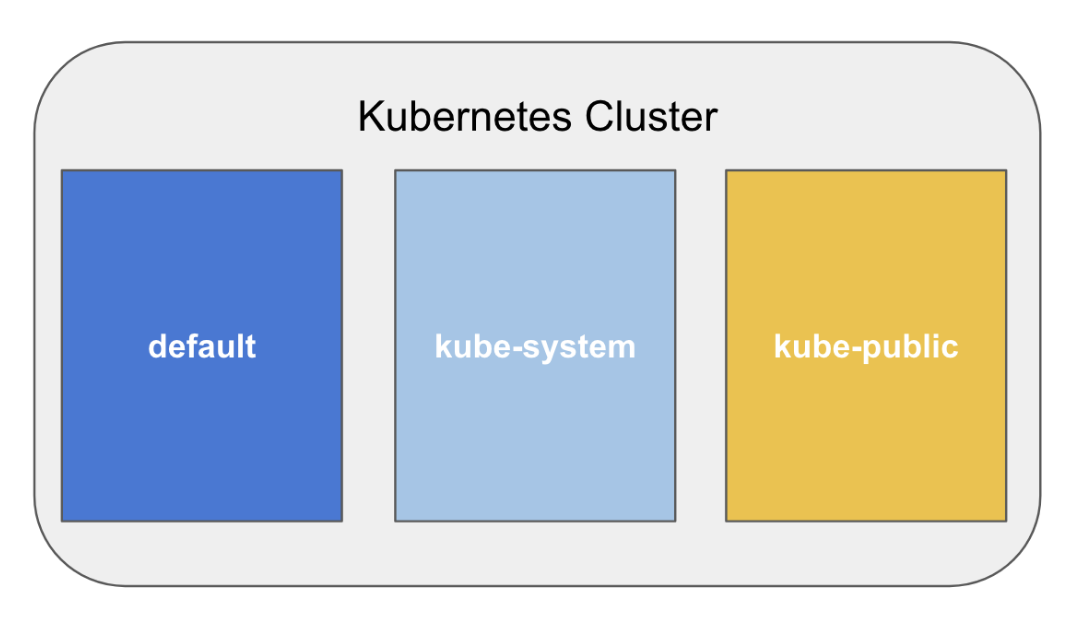
Namespace
쿠버네티스 deployment 내부의 가상 cluster입니다. 하나의 쿠버네티스 cluster 내부에 여러 namespaces가 있을 수 있고 서로 간에 분리되어 있습니다. 특정 namespace 안에 pods를 실행함으로써, 그들은 조직화, 보안, pods의 성능으로 당신의 팀을 도울 수 있습니다.
namespace는 pods을 분리하여 업무량을 분산하고, 리소스 제약 조건을 설정할 수 있는 기능을 제공합니다. namespace를 고려할 수 있는 다양한 애플리케이션 환경에 매핑할 수 있습니다.
기본적으로 쿠버네티스는 몇 개의 미리 정의된 namespaces를 가지고 있습니다.
kube-system
이 namespace 안의 pods는 쿠버네티스가 작동하는데 필요합니다.
kube-public
이 namespace는 쿠버네티스 cluster에 대한 부트스트래핑과 인증서 구성이 포함된 ConfigMap을 가지고 있습니다. 또한 이 namespace는 전체 cluster에서 보거나 읽을 수 있는 객체를 실행하는 위치로 다뤄집니다.
default
모든 객체들은 namespace를 특정하지 않으면 자동적으로 default namespace에 생성됩니다. default namespace는 삭제되지 않습니다.
Label
label은 객체들에게 공급되곤 하는 key/value 쌍으로 이루어진 특성입니다. pods가 수행하는 작업을 보다 세밀하게 제어할 수 있으므로 labels을 활용하는 것이 좋습니다. label은 특정 객체를 쿼리하는데 사용할 수 있습니다.